Cómo monitorizar nuestra Skill de Alexa
Tutorial sobre cómo monitorizar nuestra Skill con Sentry
Debuggear es esencial para los desarrolladores, pero debuggear en arquitecturas serverless requiere un enfoque totalmente diferente.
Cómo monitorizar nuestra Skill de Alexa
El backend de una Skill de Alexa es, en la mayoría de los casos, funciones serverless, usando por ejemplo, AWS Lambda. El debugging, la monitorización y las pruebas son los principales desafíos cuando se trata de arquitecturas serverless.
Las funciones serverless son, por diseño, muy difíciles de trazabilizar. Como resultado, estamos presenciando nuevas soluciones para debuggear este tipo de arquitecturas serverless, tanto local como remotamente. En este post, os presento una solución para monitorizar nuestras Skills de Alexa.
Monitorizar el interior de nuestra Skill
El Backend de nuestra Skill por naturaleza es event-driven. Esto hace que la depuración sea más difícil ya que un pequeño cambio en el contenido de un evento, su formato o el orden pueden provocar grandes diferencias durante la ejecución.
Cuando te enfrentas a un error en una Skill, reproducirlo de manera confiable puede ser la mitad de la batalla. En muchos entornos basados en eventos, el factor principal para reproducir el error es obtener los datos del evento de entrada correctos.
La migración de datos de producción a desarrollo puede llevar horas (o incluso días) y puede verse obstaculizado por la seguridad, compliance, entre otras. Las herramientas de depuración de producción permiten a los desarrolladores estudiar el error en producción sin perder tiempo y recursos en la migración de datos, y sin exponer datos confidenciales.
Hay muchas herramientas que nos ayudan a depurar y monitorizar aplicaciones sin servidor. Haciendo un estudio previo buscando cuál sería mejor para monitorizar una Skill de Alexa, elegí Sentry
¡Vamos a por ello!
Sentry
Sentry es una empresa de código abierto, que proporciona una plataforma de monitorización de aplicaciones que ayuda a identificar problemas en tiempo real. El servidor está en Python, pero contiene una API para enviar eventos desde cualquier lenguaje de programación y desde cualquier tipo de aplicación. Nos vamos a centrar en los conceptos de Sentry de Context, breadcrumbs y environments para hacer un seguimiento adecuado de nuestra Skill.
Contexts
Sentry admite contexts adicionales en los eventos. A menudo, estos contexts se comparten entre otros eventos capturados durante el ciclo de vida de nuestra Skill.
¿Qué contexts vamos a usar?:
- User: El usuario de las requests de alexa.
- Tags: nos permite clasificar y contextualizar cada request para monitorizar y rastrear bien todas las requests. Configuraremos estos tags:
- request_id: el id de la solicitud recibida.
- application_id: La id de nuestra Skill. Nos permitirá hacer una búsqueda rápida para verificar todas las requests de una Skill.
- session_id: El ID de la sesión de un usuario usando una Skill. Nos ayudará a rastrear una sesión de un usuario.
- person_id: Con la personalización, nuestra SKill puede distinguir entre usuarios individuales en la cuenta. Cuando Alexa reconoce a un usuario en concreto porque tiene reconocidas diferentes voces, además de un objeto de usuario, cada request de la Skill también incluye un objeto de
person. Este objeto contiene el valorperson_idque tambien es importante tagear para futuros filtrados.
Environments
Con los environments, podemos filtrar eventos dependiendo del entorno de ejecución, es decir, desarrollo/producción y dependiendo de la release de nuestro backend de la Skill. Por ejemplo, una versión vinculada a un despliegue de QA y esa misma versión desplegada en Producción nos aparecerá en la dashboard de Sentry para que podamos filtrar por QA y Prod.
Breadcrumbs
Sentry admite un concepto llamado Breadcrumbs. Estos son un rastro de eventos que ocurrieron antes de una execepción o, si no la hay, durante una ejecución. Muchas veces estos breadcrumbs son muy similares a los logs tradicionales, pero también tienen la capacidad de registrar datos estructurados. En estos breadcrumbs, colocaremos datos relevantes de nuestra Skill de Alexa, como requests (contextos, sesión, información del usuario), respuestas, tiempo total de ejecución, etc.
Sentry en nuestra Skill
No voy a comenzar desde cero en este post. Reutilizaré el proyecto que he usado en mi publicación Alexa Skill, AWS CloudFormation y Serverless Application Model (SAM)
Configurando Sentry en nuestra Skill
En primer lugar, lo que tenemos que agregar es la dependencia de Sentry en el archivo pom.xml:
<dependency>
<groupId>io.sentry</groupId>
<artifactId>sentry</artifactId>
<version>1.7.30</version>
</dependency>
Después de eso, necesitamos inicializar el cliente Sentry. Lo inicializaremos al mismo tiempo que se llama a la lambda con el método Sentry.init():
public class App extends SkillStreamHandler {
private static Skill getSkill() {
Sentry.init();
return Skills.standard()
.addRequestHandlers(
new CancelandStopIntentHandler(),
new HelloWorldIntentHandler(),
new HelpIntentHandler(),
new LaunchRequestHandler(),
new SessionEndedRequestHandler(),
new FallbackIntentHandler(),
new ErrorHandler())
.addExceptionHandler(new MyExceptionHandler())
.addRequestInterceptors(
new LogRequestInterceptor(),
new LocalizationRequestInterceptor())
.addResponseInterceptors(new LogResponseInterceptor())
// Add your skill id below
//.withSkillId("[unique-value-here]")
.build();
}
public App() {
super(getSkill());
}
}
Cuando se llama a Sentry.inti(), leerá el archivo sentry.properties ubicado en src/main/resources que tiene las siguientes properties:
- dsn: la URL única de nuestro proyecto Sentry. Puedes obtenerlo online en el proyecto de Sentry que hayas configurado para la Skill. Por ejemplo: ttp://fasdfasd@sentry.io/asdfas
- release: para hacer una mejor monitorización de nuestra Skill, es bueno tener esta propiedad configurada para filtrar cuando sucede algo. E.g.: 1.0, 2.0.
- environment: también es importante establecerlo para conocer el entorno actual de ejecución. E.g.: dev, prod.
- stacktrace.app.packages: el paquete de Java que quieres monitorizar. En nuestro caso
com.xavidop,alexa.helloworld
Sentry en los Interceptors de nuestra Skill
Después de agregar la dependencia y setear las properties correctamente, ahora nos vamos a centrar en nuestros dos interceptores. LogRequestInterceptor y LogResponseInterceptor. ¿Por qué esos dos?
- En el
LogRequestInterceptortenemos la request recibida que tiene toda la información que necesitamos para crear nuestros tags y el User en Sentry para trackear correctamente la request actual:public class LogRequestInterceptor implements RequestInterceptor { static final Logger logger = LogManager.getLogger(LogRequestInterceptor.class); @Override public void process(HandlerInput input) { TimeUtilities.start = new Date().getTime(); HashMap<String, String> data = new HashMap<String,String>(); //SETTING RELEVANT TAGS TO MAKE SEARCHES IN SENTRY Sentry.getContext().addTag("request_id", input.getRequestEnvelope().getRequest().getRequestId()); Sentry.getContext().addTag("application_id", input.getRequestEnvelope().getSession().getApplication().getApplicationId()); Sentry.getContext().addTag("session_id", input.getRequestEnvelope().getSession().getSessionId()); if(input.getRequestEnvelope().getContext().getSystem().getPerson() != null){ Sentry.getContext().addTag("person_id", input.getRequestEnvelope().getContext().getSystem().getPerson().getPersonId()); } //SET EXTRA USEFUL DATA FOR THE BREADCRUMB data.put("Request", input.getRequestEnvelope().getRequest().toString()); data.put("context", input.getRequestEnvelope().getContext().toString()); data.put("Session", input.getRequestEnvelope().getSession().toString()); data.put("Version", input.getRequestEnvelope().getVersion()); //CREATING THE USER OF THIS REQUEST FOR A FUTURE SEARCHES HashMap<String, Object> userData = new HashMap<String,Object>(); userData.put("device_id",input.getRequestEnvelope().getContext().getSystem().getDevice().getDeviceId()); Sentry.getContext().setUser( new UserBuilder() .setData(userData) .setUsername(input.getRequestEnvelope().getSession().getUser().getUserId()).build() ); Sentry.getContext().recordBreadcrumb( new BreadcrumbBuilder() .setLevel(Breadcrumb.Level.DEBUG) .setTimestamp(new Date()) .setData(data) .setMessage("New request recieved").build() ); logger.info(input.getRequest().toString()); } } - En el
LogResponseInterceptortenemos aquí la respuesta que vamos a enviar al dispositivo y podemos, por ejemplo, calcular el tiempo en milisegundos de la ejecución actual. Como estas son las últimas líneas de nuestra Skill durante la ejecución, una de las tareas principales de este interceptor es enviar el evento Sentry a la nube con el métodoSentry.capture(). Finalmente, limpiamos todo conSentry.clearContext()para futuras requests de Alexa:public class LogResponseInterceptor implements ResponseInterceptor { static final Logger logger = LogManager.getLogger(LogRequestInterceptor.class); @Override public void process(HandlerInput input, Optional<Response> output) { TimeUtilities.end = new Date().getTime(); HashMap<String, String> data = new HashMap<String,String>(); //GET THE RESPONSE AND PUT IT AS DATA OF THE BREADCRUMB data.put("Response", output.get().toString()); //GET THE TIME OF THE EXECUTION long time = TimeUtilities.end - TimeUtilities.start; data.put("Overall Time", String.valueOf(time) + "ms."); //CREATE A BREADCRUMB WITH THE INFO OF THE RESPONSE Sentry.getContext().recordBreadcrumb( new BreadcrumbBuilder() .setLevel(Breadcrumb.Level.DEBUG) .setTimestamp(new Date()) .setData(data) .setMessage("New response").build() ); Sentry.capture("request - " + Sentry.getContext().getTags().get("request_id")); //CLEAN CONETXT FOR NEW REQUESTS Sentry.clearContext();; logger.info(output.toString()); } }
Logging en nuestra Skill con Sentry
Una de las tareas más importantes en una arquitectura serverless es el log. Es esencial saber lo que sucedió durante una ejecución. En este ejemplo utilizaremos una clase auxiliar llamada LogUtilities que tiene un solo métodolog(String toLog) este método tiene dos tareas:
- logear utilizando las librearias log4j2 o lambda4j para tener logs estructurados.
- Crear un Breadcrumb de Sentry que se agregará al resto de breadcrumbs y estará disponible en nuestra consola Sentry como parte del evento generado por la request. Nos ayudará a rastrear lo que ha sucedido en una request. Entonces esta clase podemos llamarla donde queramos para loguear y añadir breadcrumbs. Nos ayudará a controlar y tener un buen seguimiento de nuestra Skill.
Capturando excepciones en nuestra Skill con Sentry
Por último, pero no menos importante cuando hablamos de monitorización, son las excepciones.
En nuestra ejemplo de Skill de Alexa tenemos un lugar para capturar todas las excepciones, el MyExceptionHandler. Cuando tenemos una excepción, el LogResponseInterceptor no se ejecutará. Entonces, es por eso que en este handler capturamos la excepción con Sentry y también limpiamos el contexto de Sentry para futuras requests:
public class MyExceptionHandler implements ExceptionHandler {
@Override
public boolean canHandle(HandlerInput input, Throwable throwable) {
return throwable instanceof Exception;
}
@Override
public Optional<Response> handle(HandlerInput input, Throwable throwable) {
//CAPTURING THE EXCEPTION
Sentry.capture(throwable);
//CLEANING CONTEXT
Sentry.clearContext();
return input.getResponseBuilder()
.withSpeech("An error was encountered while handling your request. Try again later.")
.build();
}
}
El poder de Sentry
Ahora que ya hemos configurado nuestra Skill con Sentry. Enviaremos una request de Alexa a nuestro servidor y luego revisaremos la consola de Sentry:
WOW!!, tenemos una nueva entrada!
 Dashboard
Dashboard
Ahora haz clic en el evento y veamos qué hay dentro:
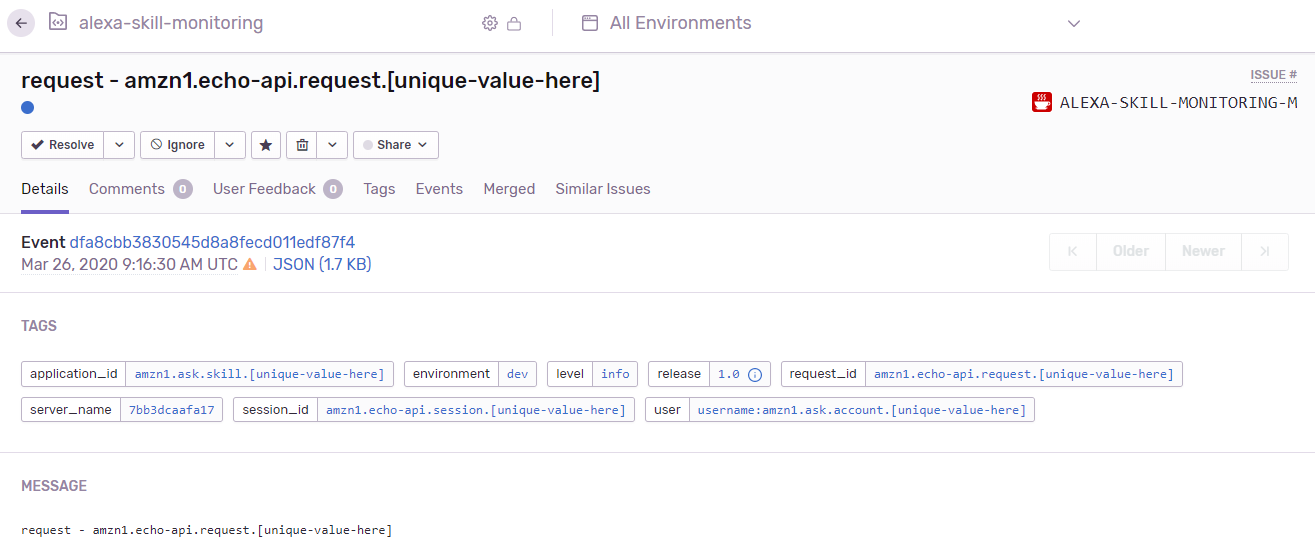 Tags
Tags
Aquí tienes la información del evento: hora de la request de Alexa y todos los tags. Se puede hacer clic en cada tag para filtrar según nuestras necesidades.
Si nos desplazamos hacia abajo, veremos los breadcrumbs. Una vista rápida de lo que sucedió durante la request:
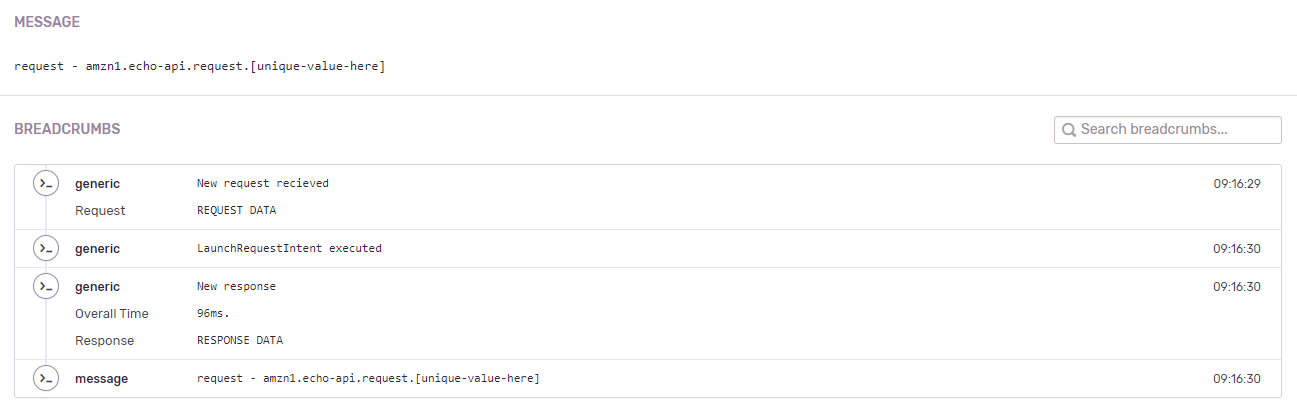 Breadcrumbs
Breadcrumbs
NOTA: Los datos de la request y la respuesta se han eliminado para este ejemplo.
Si continuamos desplazándonos hacia abajo, veremos la información de Usuario (id de usuario de Alexa e id del dispositivo de Alexa) y la información sobre el SDK de Sentry utilizado.
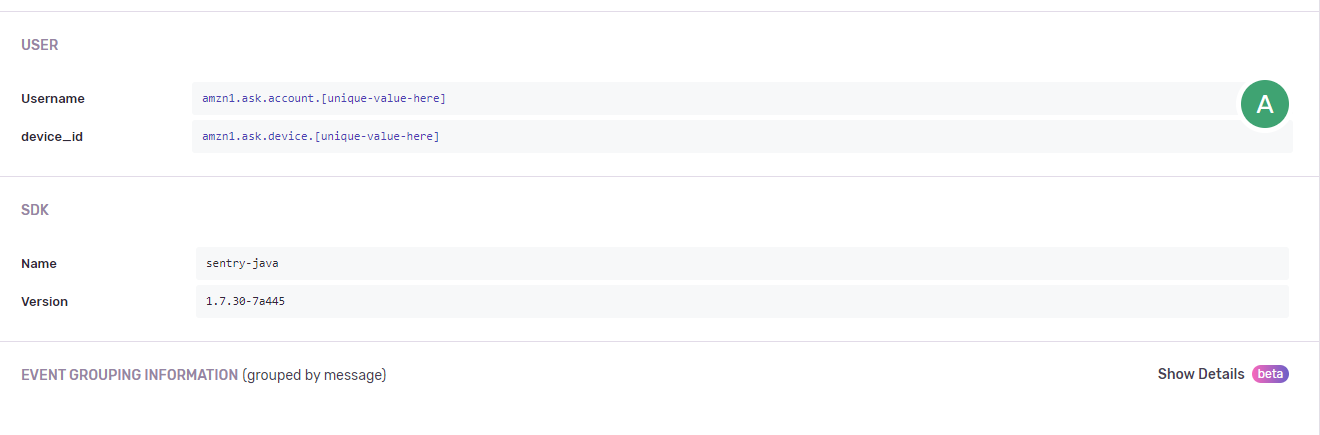 Usuario
Usuario
Si tenemos una excepción, también podemos verla en el dashboard de Sentry:
 Excepción en el dashboard
Excepción en el dashboard
También podemos ver toda la información de ejecución haciendo click en la excepción:
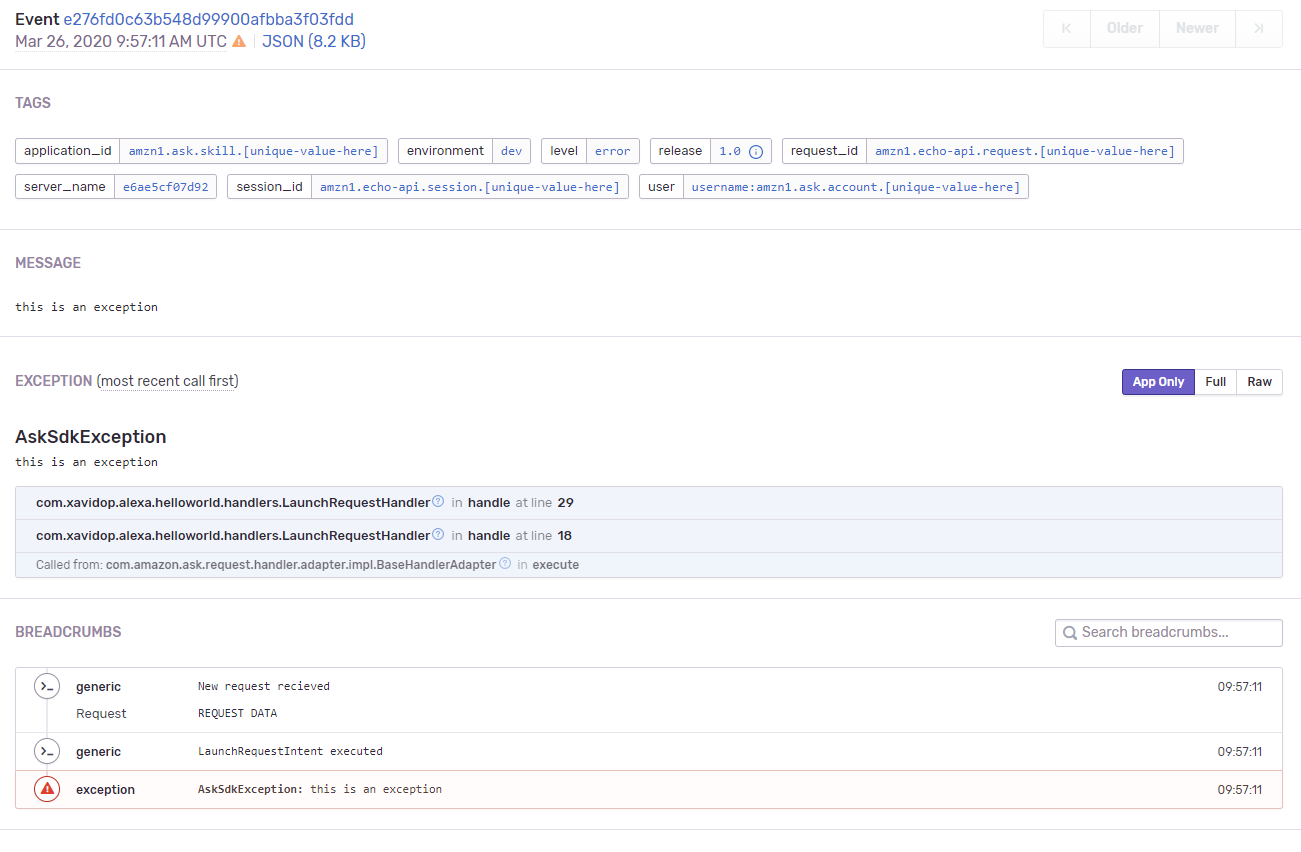 Excepción
Excepción
Puedes ver el stacktrace completo de la excepción haciendo click en el botón Raw:
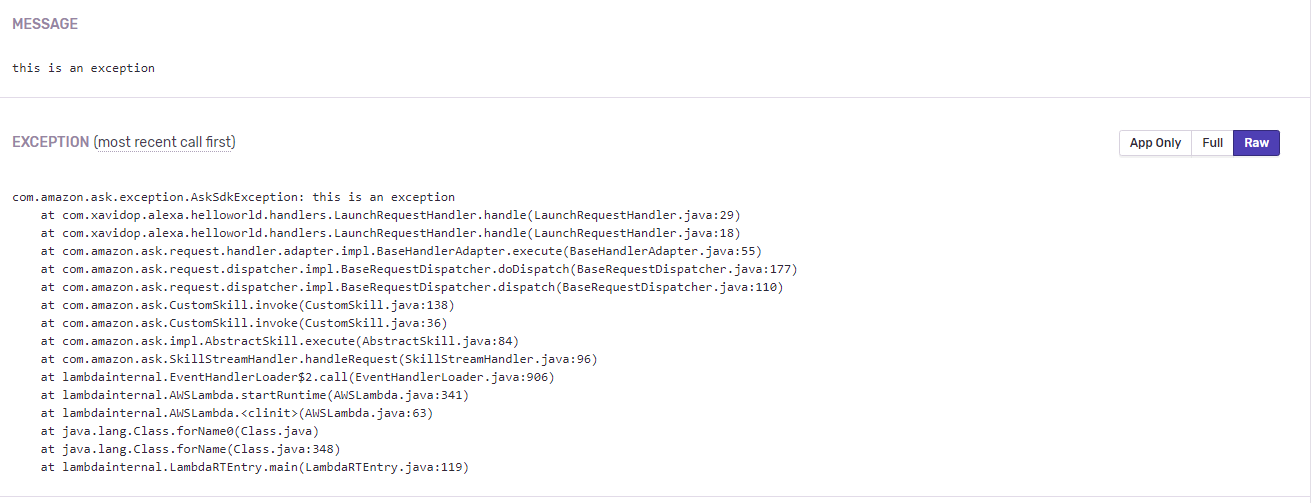 Stacktrace de la Excepción
Stacktrace de la Excepción
Antes de concluir este punto, me gustaría añadir que con Sentry podemos realizar búsquedas de cualquier tag, user, environment o release que se haya registrado a través de los eventos enviados.
Por ejemplo:
- Dame todas las requests de Alexa que vinieron de un usuario y una Skill específica:
- request_id:amzn1.echo-api.request.[unique-value-here] application_id:amzn1.ask.skill.[unique-value-here]
- Dame todas las requests de Alexa que vinieron de una sesión:
- session_id:amzn1.echo-api.session.[unique-value-here]
- Dame todas las reuqests de Alexa que vinieron de la release actual:
- release:XXX
Puedes guardar estas búsquedas para que estén disponibles con un solo clic.
Conclusión
Con la ayuda de Sentry, pasamos rápidamente de tener cero conocimiento a comprender el error y lo que ocurre en nuestra Skill.
He hecho este ejemplo en Java, pero puedes usarlo en otros lenguajes compatibles con Alexa porque Sentry está disponible en muchos lenguajes de programación como NodeJS, Python, Java, Kotlin, C#, PHP, Ruby, Go, iOS Android, etc.
Puedes echar un vistazo a toda la documentación de Sentry aquí
En cuanto a los precios, Sentry tiene un plan de developer que viene con 5.000 eventos gratis al mes. En nuestro caso, 5.000 requests de Alexa de nuestras Skills. Puedes ver los planes aquí
Puedes encontrar el código en mi Github
!Eso es todo!
¡Espero que te sea útil! Si tienes alguna duda o pregunta, no dudes en ponerte en contacto conmigo o poner un comentario a continuación.
Happy coding!