Vercel AI SDK Middleware vs Genkit Middleware: a Hands-On Comparison (English)
A side-by-side comparison of the two leading middleware systems in the JS/TS Gen AI ecosystem: Vercel AI SDK’s wrapLanguageModel and Genkit’s generateMiddleware. APIs, mental model, built-ins, composition, observability and when to pick each.
- Introduction
- TL;DR
- The mental model
- The hooks side by side
- Built-ins, head to head
- Composition
- Per-request metadata
- Streaming
- Tools and agents
- Observability and tracing
- A concrete decision guide
- Conclusion
Introduction
Two of the most popular Gen AI frameworks in JavaScript/TypeScript, Vercel AI SDK and Genkit, both ship a middleware system to extend their model calls with cross-cutting behavior: logging, caching, RAG, retries, fallbacks, guardrails, tool approval, etc.
On the surface they look very similar. In practice, they sit at different abstraction levels and embody different philosophies. This article puts them side by side using their official docs as the source of truth:
I’ll walk through the API surface, the built-ins, how composition works, how you write your own, and finish with a concrete decision matrix.
One scope note before we dive in: Vercel AI SDK is JavaScript/TypeScript only, while Genkit is a multi-language framework with official SDKs for JavaScript/TypeScript (primary, stable), Go, Python (preview) and Dart/Flutter (preview), plus a community-maintained Java SDK. The middleware comparison below is JS/TS-to-JS/TS, but if you also need to share patterns with Go, Python, Dart or Java services, that is a Genkit-only conversation.
TL;DR
| Topic | Vercel AI SDK | Genkit |
|---|---|---|
| Primitive | wrapLanguageModel({ model, middleware }) returns a wrapped model | use: [...] array on each generate() call |
| Granularity | Wraps the language model (doGenerate / doStream) | Wraps the model, tool execution, and generation loop |
| Hooks | transformParams, wrapGenerate, wrapStream | model, tool, generate |
| Where to put it | At model construction (provider-agnostic, model-level) | At call site (per-request, declarative) |
| Built-ins | Reasoning extraction, JSON extraction, simulated streaming, default settings, tool input examples | Filesystem, Skills, Tool approval, Retry, Fallback |
| Streaming | First-class (separate wrapStream) | Handled inside the model hook |
| Per-request metadata | providerOptions namespaced by middleware name | Direct config object passed when invoking the middleware |
| Distribution | Provider-agnostic, follows LanguageModelV3Middleware spec | Follows the generateMiddleware contract (with Zod config schemas) |
Both are good. They are designed for different mental models and you can absolutely use both in the same codebase if you mix the two SDKs.
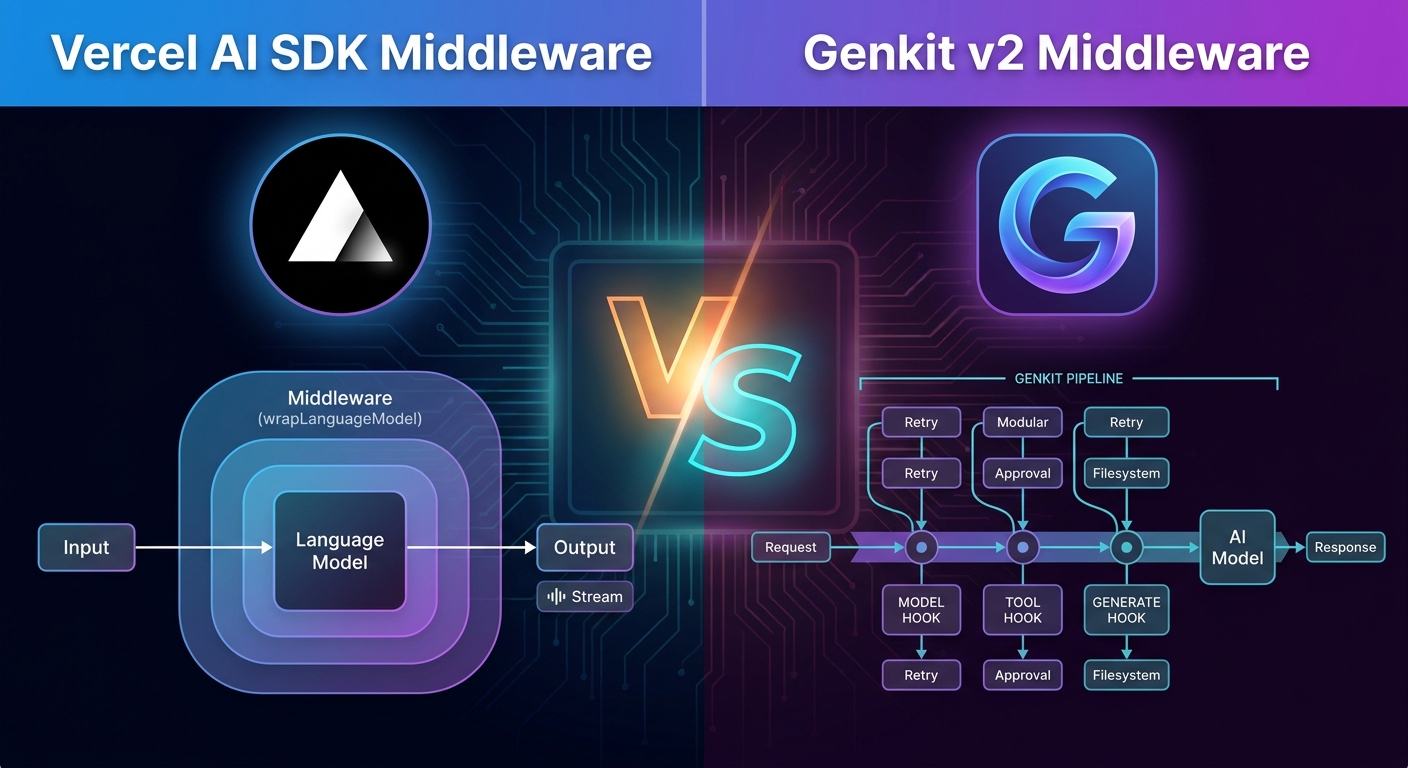
The mental model
Vercel AI SDK: wrap the model
In Vercel’s world, middleware is a decorator over the language model itself. You take a model, wrap it, and the result is “still a model”. It plugs into generateText, streamText, generateObject, etc. without those functions even knowing middleware exists.
import { wrapLanguageModel, streamText } from 'ai';
const wrappedLanguageModel = wrapLanguageModel({
model: yourModel,
middleware: yourLanguageModelMiddleware,
});
const result = streamText({
model: wrappedLanguageModel,
prompt: 'What cities are in the United States?',
});
This is very clean: the middleware travels with the model and is transparent to the rest of your code.
Genkit: opt in per call
Genkit takes the opposite stance. Instead of wrapping the model, you pass middlewares as part of each generate() call via the use: array, and you can intercept three different phases of the pipeline: the model, the tools, and the high-level generate loop.
const response = await ai.generate({
model: googleAI.model('gemini-flash-latest'),
prompt: 'Hello',
use: [retry({ maxRetries: 3 }), loggerMiddleware({ verbose: true })],
});
Trade-off: it is more explicit (you see exactly what runs at each call site), at the cost of being noisier when you want a global behavior. Both styles are easy to wrap in a small helper.
The hooks side by side
Vercel AI SDK
Three hooks, all centered on the language model contract:
transformParams— mutate the request before it hitsdoGenerateordoStream.wrapGenerate— wrap the non-streaming call, observe and modify the result.wrapStream— wrap the streaming call. You typically pipe the stream through aTransformStreamto inspect or rewrite chunks.
Example: the canonical logging middleware, including streaming:
import type {
LanguageModelV3Middleware,
LanguageModelV3StreamPart,
} from '@ai-sdk/provider';
export const yourLogMiddleware: LanguageModelV3Middleware = {
wrapGenerate: async ({ doGenerate, params }) => {
console.log('doGenerate called', params);
const result = await doGenerate();
console.log('generated text:', result.text);
return result;
},
wrapStream: async ({ doStream, params }) => {
const { stream, ...rest } = await doStream();
let generatedText = '';
const transformStream = new TransformStream<
LanguageModelV3StreamPart,
LanguageModelV3StreamPart
>({
transform(chunk, controller) {
if (chunk.type === 'text-delta') generatedText += chunk.delta;
controller.enqueue(chunk);
},
flush() {
console.log('stream finished:', generatedText);
},
});
return { stream: stream.pipeThrough(transformStream), ...rest };
},
};
Genkit
Three hooks too, but cutting along execution phase instead of stream vs non-stream:
model— wraps the model invocation. Streaming and non-streaming go through the same hook.tool— wraps tool execution. This has no equivalent in Vercel’s spec (tools are not part of the language-model middleware contract there).generate— wraps the entire high-level generation loop, including tool calling and output parsing.
import { generateMiddleware, z } from 'genkit';
export const loggerMiddleware = generateMiddleware(
{
name: 'loggerMiddleware',
description: 'Logs requests and responses',
configSchema: z.object({ verbose: z.boolean().optional() }),
},
({ config }) => ({
model: async (req, ctx, next) => {
if (config?.verbose) console.log('Request:', JSON.stringify(req));
const resp = await next(req, ctx);
if (config?.verbose) console.log('Response:', JSON.stringify(resp));
return resp;
},
})
);
Two important differences:
- Tools are first-class citizens in Genkit middleware. You can intercept tool execution itself, which is exactly what powers
toolApproval. In Vercel AI SDK, tool gating typically lives in your application code or insideexperimental_prepareStepfor agents, not in the middleware spec. - Genkit middleware factories carry a Zod config schema, so misconfigured middleware fails fast with a clear error. Vercel middleware is a plain object that conforms to
LanguageModelV3Middleware; configuration is your responsibility.
Built-ins, head to head
Vercel AI SDK
Centered on adapting the model contract to real-world quirks:
extractReasoningMiddleware— pulls<think>...</think>blocks (and similar) out of the text and surfaces them as areasoningproperty. Crucial for DeepSeek R1 and friends.extractJsonMiddleware— strips Markdown code fences from JSON outputs soOutput.object()keeps working with chatty models.simulateStreamingMiddleware— fakes a streaming interface on top of a non-streaming model, so your UI code stays consistent.defaultSettingsMiddleware— pins default settings (temperature, max output tokens, provider options).addToolInputExamplesMiddleware— for providers that don’t supportinputExamplesnatively, serializes them into the tool description.
The theme is clear: smooth over differences between providers. Vercel runs an SDK that has to talk to dozens of model providers, so its middleware library reflects that.
Genkit
Centered on production patterns and agentic behavior:
filesystem— sandboxed file tools (list_files,read_file,write_file,search_and_replace) restricted to a root directory.skills— auto-injectsSKILL.mdfiles into the system prompt and exposes ause_skilltool.toolApproval— human-in-the-loop gating for tool calls, with first-classToolInterruptErrorand resume support.retry— exponential backoff with jitter for transient errors.fallback— automatic switch to a different model on failure.
Theme: production hardening and agent ergonomics. Genkit assumes you’ll plug in your own providers but want batteries for retry/fallback/approval/skills.
Notice the very small overlap. If you wanted “extract reasoning” in Genkit you’d write it as a custom middleware (10-20 lines). If you wanted “retry with backoff” in Vercel AI SDK, same thing. Each ecosystem chose to ship the middlewares its users were asking for the most.
Composition
Vercel AI SDK
You pass an array to wrapLanguageModel. The order is “outermost first”: the first middleware in the array runs outside the second one.
const wrappedLanguageModel = wrapLanguageModel({
model: yourModel,
middleware: [firstMiddleware, secondMiddleware],
});
// applied as: firstMiddleware(secondMiddleware(yourModel))
Composition is static. The wrapped model is a long-lived value. Great for “configure once at startup” scenarios.
Genkit
You pass an array to use: on every call. Order is the same onion model: outer middlewares wrap inner ones.
const response = await ai.generate({
model: googleAI.model('gemini-pro-latest'),
prompt: userPrompt,
use: [
loggerMiddleware({ verbose: false }),
retry({ maxRetries: 3 }),
fallback({
models: [googleAI.model('gemini-flash-latest')],
statuses: ['RESOURCE_EXHAUSTED'],
}),
toolApproval({ approved: ['searchDocs'] }),
],
});
Composition is dynamic. You can change the stack per request based on user, tenant, A/B test, environment, etc. without rebuilding model instances.
Per-request metadata
A common need is to pass per-request context (user id, tenant, trace id…) into a middleware.
Vercel AI SDK uses providerOptions, namespaced by the middleware name:
export const yourLogMiddleware: LanguageModelV3Middleware = {
wrapGenerate: async ({ doGenerate, params }) => {
console.log('METADATA', params?.providerMetadata?.yourLogMiddleware);
return doGenerate();
},
};
await generateText({
model: wrapLanguageModel({ model: 'anthropic/claude-sonnet-4.5', middleware: yourLogMiddleware }),
prompt: 'Invent a new holiday and describe its traditions.',
providerOptions: {
yourLogMiddleware: { hello: 'world' },
},
});
Genkit is more direct: middleware is invoked as a factory, so you pass config when you instantiate it for that call:
use: [loggerMiddleware({ verbose: true, requestId: 'abc-123' })],
Both work, but the Genkit approach is type-checked end-to-end thanks to the Zod config schema, while Vercel’s providerOptions is more loosely typed.
Streaming
Vercel AI SDK has separate hooks for streaming and non-streaming, which is honest because the two have very different semantics. You almost always need to pipe the stream through a TransformStream.
Genkit folds streaming into the same model hook. The middleware sees the request and the response, and the underlying engine handles whether it was streamed. This is more ergonomic when your middleware doesn’t need per-chunk logic, but if you do need to inspect chunks (say, for guardrails on partial output), you’ll need to drop down to lower-level APIs.
Tools and agents
This is where the two systems diverge most.
In Vercel AI SDK, tools live above the middleware layer. The LanguageModelV3Middleware spec sits at the model level; agentic loops are handled by higher-level abstractions like generateText, streamText and the agent APIs (experimental_prepareStep, etc.).
In Genkit, the tool and generate hooks make tool execution and the agent loop first-class targets for middleware. This is what enables clean implementations of:
- Tool approval (
toolApproval) - Tool sandboxing (
filesystem) - Agent-level skill injection (
skills)
If you build a lot of agents with tool calling, Genkit’s middleware surface is genuinely more expressive.
Observability and tracing
Both frameworks are observable but in different shapes:
- Genkit has a built-in Developer UI that shows traces of every
generate()call, including middleware, tools, and nested flows. Middleware automatically participates in traces. - Vercel AI SDK is OpenTelemetry-friendly and integrates naturally with Vercel’s
@vercel/otel, AI Gateway and Vercel Observability. You can wire your middleware into spans yourself.
If “open the Dev UI and see what every middleware did” is high on your list, Genkit wins. If you already live inside the Vercel platform, the AI SDK plays beautifully with the rest of the stack.
A concrete decision guide
I would reach for Vercel AI SDK middleware when:
- I want a very small, well-defined surface area: tweak params, wrap generate, wrap stream.
- I am bouncing between many model providers and need normalization (reasoning extraction, JSON cleanup, default settings).
- I prefer “configure the model once at startup” over “compose per call”.
- I am already deep in the Vercel ecosystem (Next.js, AI Gateway, Vercel Observability).
- Streaming-aware behavior with per-chunk transforms is a hard requirement.
I would reach for Genkit middleware when:
- I am building agents with tool calling, and I need tool approval, sandboxing or skill injection.
- I want production-grade
retryandfallbackbehavior out of the box. - I want to compose middleware per request based on user, tenant or experiment.
- I value the Developer UI and rich tracing over my entire pipeline.
- I want typed, validated middleware configuration via Zod.
And honestly, in many real systems you might use both: Vercel AI SDK on the front-end / edge for chat UX, and Genkit on the backend for orchestration, tool calling and agentic flows. The middleware contracts are scoped, you won’t get the kind of conflicts you would expect.
Conclusion
Vercel AI SDK middleware and Genkit middleware are two well-thought-out answers to the same question, asked from different vantage points.
- Vercel AI SDK treats middleware as a provider abstraction layer: you adapt and normalize what providers give you.
- Genkit treats middleware as a production-pipeline composition layer: you orchestrate models, tools and agentic loops with reusable building blocks.
Pick the one that matches the shape of your problem, and don’t be afraid to mix them. The best part of 2026 in JS/TS Gen AI is that both are mature, both are open source, and both let you write your own middleware in a handful of lines.
Further reading: